In the world of AI, Retrieval-Augmented Generation (RAG) has become the gold standard for grounding Large Language Models (LLMs) with external, factual knowledge. But if you’ve deployed a RAG system, you might have noticed something: the out-of-the-box configurations often fall short. Your LLM might still hallucinate, retrieve irrelevant information, or simply fail to understand complex queries.
The reason isn’t in the LLM: it’s in your data. The true power of a production-grade RAG system is unlocked not through bigger models, but through smarter data preparation. This comprehensive guide will take you on a deep dive into the two most critical levers for boosting your RAG system’s accuracy and performance: optimizing chunking strategies and refining embedding models. We’ll show you how to move beyond basic setups and build a robust, reliable RAG pipeline with practical Python examples that you can implement today.
Why Your RAG System Needs an Upgrade: The Foundation of Performance
A successful RAG pipeline is built on two interdependent components: the retriever and the generator.
- The Retriever: This component’s job is to intelligently search your knowledge base and pull out the most relevant pieces of information, or “chunks,” that directly address the user’s query.
- The Generator: The LLM then uses these retrieved chunks as factual context, ensuring its response is accurate, relevant, and free from fabricated details.

The entire system’s reliability hinges on the retriever’s ability to find the right chunks. This is a direct function of how your documents are chunked and how those chunks are embedded into a searchable format. A subpar chunking strategy can break up a crucial sentence, while a weak embedding model can fail to capture the true semantic meaning of your data, leading to irrelevant retrievals and a frustrating user experience.
Think of it like this: if your knowledge base is a vast library, your chunking strategy determines how the books are organized, and your embedding model acts as the card catalog. A good system ensures you always find the exact passage you need.
Advanced Chunking Strategies for Improved RAG Performance
Chunking is the art of breaking down large documents into smaller, meaningful segments. The right strategy can make the difference between a high-performing RAG system and one that consistently fails. Let’s explore the techniques that professionals use.
1. Fixed-Size Chunking (The Starting Point)
This is the simplest method, splitting documents into equal-sized chunks based on a fixed token count. It’s a good starting point for structured data like FAQs or glossaries, where semantic boundaries are less critical.
from langchain_text_splitters import CharacterTextSplitter
# Read text from a file
with open("sample_rag_text.txt", "r", encoding="utf-8") as file:
text = file.read()
# Initialize the text splitter
splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=0,
length_function=len
)
# Split the text into chunks
chunks = splitter.split_text(text)
# Output
print(f"Number of chunks: {len(chunks)}\n")
for i, chunk in enumerate(chunks, start=1):
print(f"--- Chunk {i} ---\n{chunk}\n")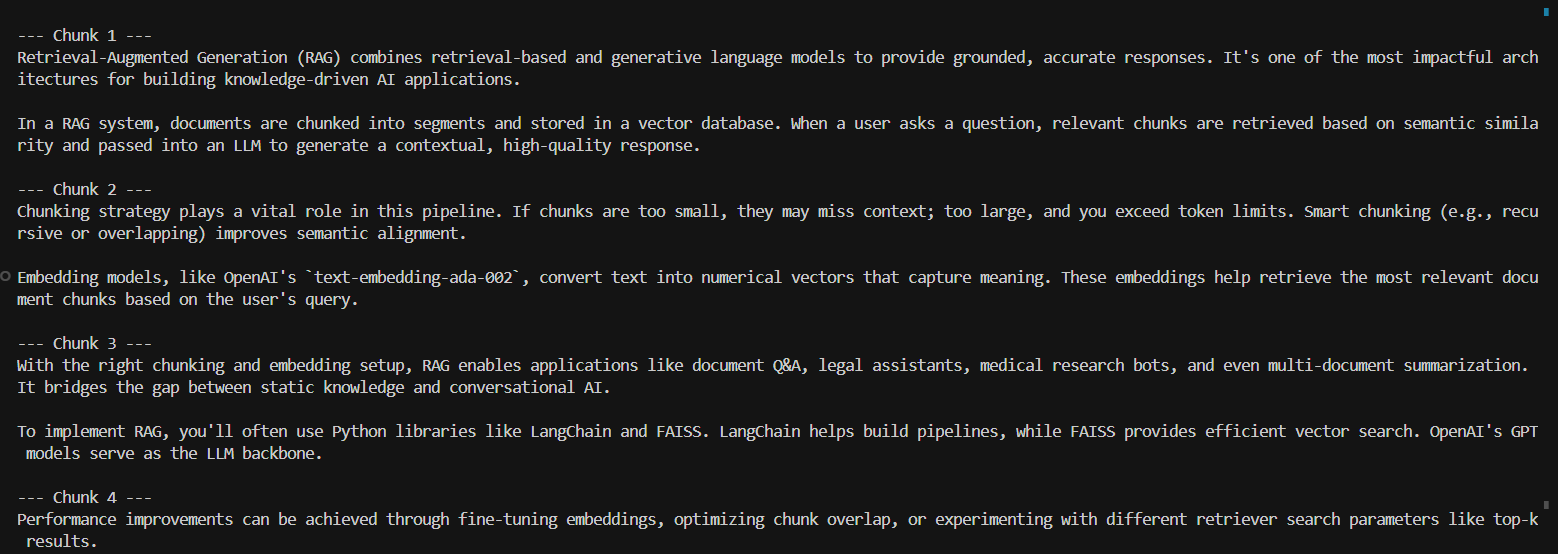
When to use: For documents where content is already logically separated, such as a database of short articles or a collection of bullet points.
2. Overlapping Chunking (Preserving Context)
The fixed-size approach can be problematic because a critical piece of context might be split between two chunks. Overlapping chunking solves this by adding a small overlap between consecutive chunks, ensuring that the semantic link between them is never lost. This is a crucial technique for documents where the context flows from one paragraph to the next.
from langchain_text_splitters import CharacterTextSplitter
with open("sample_rag_text.txt", "r", encoding="utf-8") as file:
text = file.read()
splitter = CharacterTextSplitter(
separator="\n\n",
chunk_size=500,
chunk_overlap=100,
length_function=len
)
chunks_overlap = splitter.split_text(text)
print(f"Number of overlapping chunks: {len(chunks_overlap)}\n")
for i, chunk in enumerate(chunks_overlap, start=1):
print(f"--- Overlapping Chunk {i} ---\n{chunk}\n")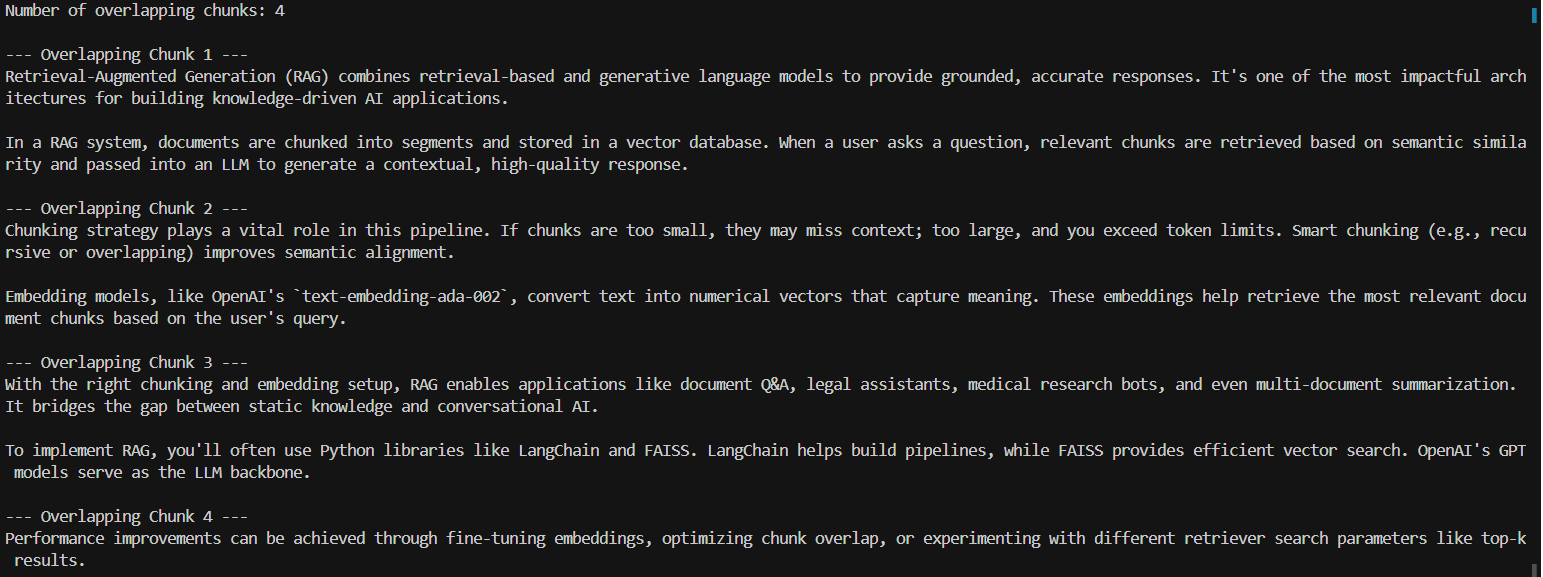
When to use: For long-form articles, reports, or documentation where context is fluid and spans across sentences or paragraphs.
3. Recursive & Semantic Chunking (The Gold Standard)
For complex, unstructured content like research papers or books, you need a more intelligent approach. Recursive character text splitting attempts to split text using a list of separators, starting with the largest (e.g., \n\n for paragraphs) and moving to smaller ones (e.g.,., ). This method prioritizes keeping semantically related text together, resulting in much more meaningful chunks for your RAG retriever.
from langchain_text_splitters import RecursiveCharacterTextSplitter
with open("sample_rag_text.txt", "r", encoding="utf-8") as file:
text = file.read()
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
chunks_recursive = splitter.split_text(text)
print(f"Number of recursive chunks: {len(chunks_recursive)}\n")
for i, chunk in enumerate(chunks_recursive, start=1):
print(f"--- Recursive Chunk {i} ---\n{chunk}\n")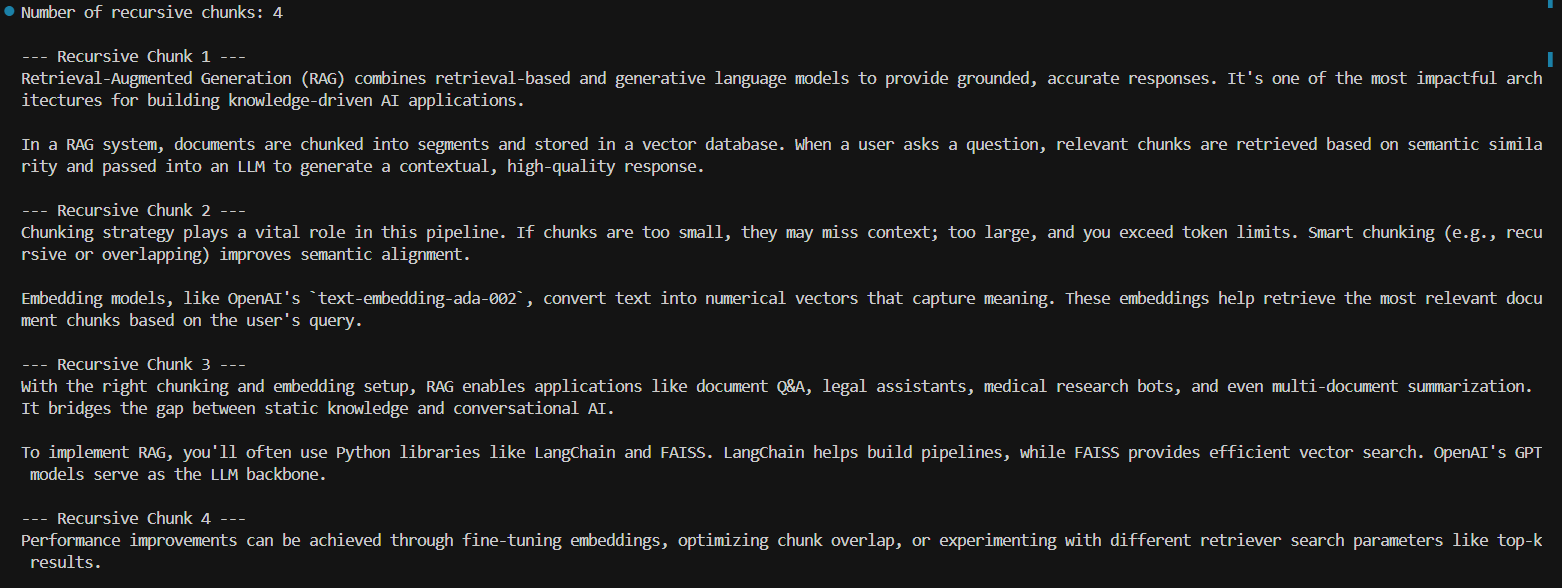
When to use: For virtually all unstructured data where semantic boundaries are not immediately obvious. This is the recommended method for building robust RAG pipelines.
Embedding Optimization: Supercharging Your Retrieval Accuracy
Once you have your perfectly chunked data, the next step is to convert each chunk into an embedding—a numerical vector that captures its semantic meaning. The right embedding model and strategy are the key to a retrieval system that understands not just keywords, but also the underlying intent of a query.
1. Optimal Model Selection
Choosing the right embedding model is perhaps the most impactful decision you can make. While generic models like all-mpnet-base-v2 are excellent for general-purpose text, you should consider domain-relevant models for specialized knowledge bases (e.g., models fine-tuned on legal, medical, or financial texts). OpenAI’s text-embedding–ada-002 is a widely-used, high-performance option.
from langchain_openai import OpenAIEmbeddings
# Read from file
with open("sample_rag_text.txt", "r", encoding="utf-8") as file:
text = file.read()
# Take first 500 characters for embedding
sample_chunk = text[:500]
embedding_model = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key="your-openai-api-key"
)
sample_embedding = embedding_model.embed_query(sample_chunk)
print(f"Embedding vector dimension: {len(sample_embedding)}")2. The Dimensionality Trade-Off
Embeddings come in different dimensions (e.g., 768, 1536). Higher-dimensional embeddings can capture more nuance but also require more storage and computational power for vector similarity searches. It’s a crucial trade-off to consider when building scalable RAG solutions.
3. Fine-Tuning for Domain-Specificity
For the ultimate retrieval accuracy, especially in highly specialized fields, you can fine-tune a pre-trained embedding model on your own domain data. This process teaches the model the unique terminology and semantic relationships within your knowledge base, leading to significant performance gains and near-perfect retrieval for even the most complex queries.
Step-by-Step RAG Pipeline with Optimized Chunking & Embeddings
Let’s build a simple yet powerful RAG pipeline using our optimized chunks and embeddings, leveraging a robust vector store like FAISS and a powerful LLM from OpenAI.
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.chains import RetrievalQA
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Read document
with open("sample_rag_text.txt", "r", encoding="utf-8") as file:
long_document = file.read()
# Step 1: Chunk
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
chunks = splitter.split_text(long_document)
docs = [Document(page_content=chunk) for chunk in chunks]
# Step 2: Embed
api_key = "Your-API-Key"
embedding_model = OpenAIEmbeddings(model="text-embedding-ada-002", openai_api_key=api_key)
db = FAISS.from_documents(docs, embedding_model)
# Step 3: LLM
llm = ChatOpenAI(model_name="gpt-4", temperature=0, openai_api_key=api_key)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=db.as_retriever(search_kwargs={"k": 2}),
return_source_documents=True
)
# Step 4: Query
query = "What is RAG and why does chunking matter?"
response = qa_chain.invoke({"query": query})
# Step 5: Output
print(f"**Query:** {query}")
print(f"**Answer:** {response['result']}")
print(f"**Source Documents:**")
for i, doc in enumerate(response["source_documents"], start=1):
print(f"\nSource #{i}:\n{doc.page_content}")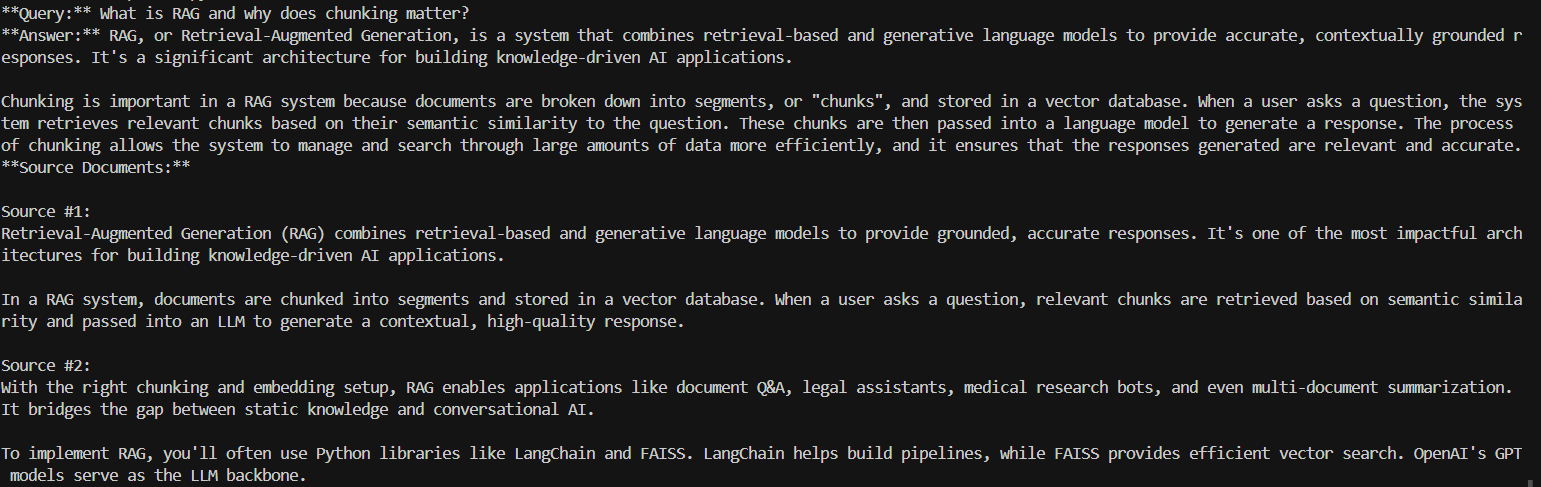
This final pipeline demonstrates how optimized chunking and embeddings directly translate into a more accurate, context-aware, and reliable response from your RAG-powered LLM.
Elevate Your RAG: Building a Production-Ready Pipeline
In the race for AI dominance, the ability to build reliable, high-performance RAG systems is a non-negotiable competitive advantage. The tools and techniques are accessible, but their effective implementation requires a nuanced understanding of your data.
By thoughtfully implementing advanced chunking strategies and refining your embedding models, you can drastically improve the relevance and precision of your RAG pipeline. Your LLM will become a more trustworthy and powerful tool, and your users will benefit from faster, more accurate, and more relevant responses.
Ready to transform your RAG system from a proof-of-concept into a robust, production-ready solution? Our team at Veritas Analytica specializes in designing and deploying custom enterprise-grade RAG solutions and vector databases that deliver exceptional performance.


