Hi readers!
Are you ready to take your machine-learning models to the next level? In this guide, we’ll dive into how you can leverage Retrieval-Augmented Generation (RAG) using the Groq API in Python.
Whether you’re a seasoned developer or just exploring new AI technologies, this step-by-step tutorial will walk you through everything you need to know.
But before we jump into the code, let’s ensure we’re on the same page with the key concepts that will make this implementation a breeze.
What is a Large Language Model (LLM)?
LLMs(Large Language Models) are machine learning models that belong to the deep learning family and are pre-trained on vast amounts of data. They work on the transformer architecture that consists of the neural networks having encoders and decoders with self-attention capabilities.
What is Groq?
Groq is an LLM inference company that provides access to the LLMs via API. LLMs are hosted on the custom hardware of Groq, which they call Language Processing Units (LPUs).
What is Retrieval Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is an LLM optimization technique that enables it to provide references from a custom knowledge base outside its training data sources. This helps LLMs to generate domain-specific, authentic, and context-aware responses without retraining the model.
Benefits of RAG
RAG capabilities provide several benefits to organizations to enhance their LLMs capabilities.
- Cost Effectiveness
Training an LLM requires a lot of computing resources, technical knowledge, and time. If we take the training path to adopt LLMs to our specific knowledge base, it will consume resources. On the other hand, implementing RAG on LLMs to adapt them to specific industries is a cost-effective solution.
- Improves Credibility
Other than cost-effectiveness, RAGs improve the credibility of LLM responses. They provide the proper reference for the information source, making LLM more credible. If users want to verify this information, they can check the source themselves.
- Accurate information
If we don’t utilize the RAGs, LLM will provide the responses from the data on which it is trained, not the updated information. Utilizing RAGs enables LLMs to provide more accurate and up-to-date responses from current data sources incorporated using RAGs.
Implementation of RAG by Using Groq API
In this implementation, we are going to use the RAG with the Groq API on a Mixtral model (“mixtral-8x7b-32768”). We will ask the LLM about US President James Garfield’s views on civil service reform, and then we will provide the data of all presidential speeches to the LLM using RAG. We will ask the same question again after RAG and check LLM’s response.
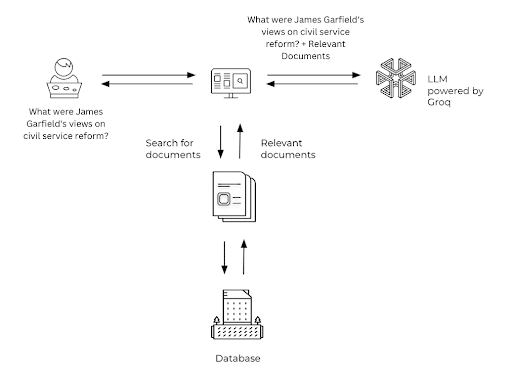
Now, let’s jump into the implementation and get our hands dirty with the code. But first, make sure you have a prerequisite.
Prerequisite:
- A Groq API key
- A Hugging Face user access token
- Dataset
- Your favorite code editor
Response from LLM
Before we dive into the RAG implementation, let’s have a look at the response of LLM without RAG.
Here is the user question;
user_question = "What were James Garfield's views on civil service reform?"And here is the LLM response;
James Garfield, the 20th President of the United States, held strong views on civil service reform. Prior to his presidency, he had served as a member of the House of Representatives where he was a vocal advocate for reforming the civil service system.
In 1877, while serving as a representative, Garfield delivered a speech on the subject of civil service reform in which he stated:
"Now, therefore, I ask, if it be not better to appoint, as far as practicable, all subordinate officers on their merits and fitness, by competitive examination, giving to each applicant equal opportunity and fair justice?"
Garfield believed that the civil service system at the time was plagued by corruption and nepotism, and that the appointment of government officials should be based on merit rather than political connections.
After his election as President in 1881, Garfield continued to advocate for civil service reform. In his inaugural address, he stated:
"The civil service of the United States must be preserved in accordance with the law. I shall discourage every attempt to supersede merit by patronage. I believe that it is not only the right and the privilege, but the duty, of the Executive to be guided by a high sense of honor and integrity in the appointment of officials; and it is the duty of Congress to cooperate with the Executive in maintaining a clean and pure administration of the law in every department of the Government."
Unfortunately, Garfield's presidency was cut short by his assassination just four months after taking office, and he was unable to implement the civil service reforms he had proposed. However, his advocacy for the issue helped to pave the way for the Pendleton Civil Service Reform Act of 1883, which established a merit-based system for appointing federal employees.Now, if you check this response model, it is hallucinating. Its response is not accurate, and there is a lot of extra information in it without proper attribution.
Next, we will use RAG to overcome these issues.
Step by Step implementation of RAG:
First of all, open your favorite code editor or IDE. I am using Google Colab in this tutorial.
1. Install Necessary Libraries
pip install groq pip install langchain langchain-community pip install huggingface_hub pip install tiktoken pip install sentence-transformers
2. Import Required Dependencies
import pandas as pd import numpy as np from groq import Groq import os from langchain_community.vectorstores import Chroma from langchain.text_splitter import TokenTextSplitter from langchain.docstore.document import Document from langchain_community.embeddings.sentence_transformer import SentenceTransformerEmbeddings from langchain_pinecone import PineconeVectorStore from transformers import AutoModelForCausalLM, AutoTokenizer from sklearn.metrics.pairwise import cosine_similarity from IPython.display import display, HTML
3. Set Up Your Groq API Key
groq_api_key = "YOUR GROQ API KEY HERE" client = Groq(api_key = groq_api_key)
4. Load the Dataset
presidential_speeches_df = pd.read_csv('/presidential_speeches.csv')
presidential_speeches_df.head()
5. Set Up Hugging Face Token
from huggingface_hub import notebook_login notebook_login()
6. Tokenize the Single Speech from the Dataset
garfield_inaugural = presidential_speeches_df.iloc[309].Transcript
model_id = "meta-llama/Meta-Llama-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# create the length function
def token_len(text):
tokens = tokenizer.encode(
text
)
return len(tokens)
token_len(garfield_inaugural)
7.Split the Text in Chunks
text_splitter = TokenTextSplitter(
chunk_size=450, # 500 tokens is the max
chunk_overlap=20 # Overlap of N tokens between chunks (to reduce chance of cutting out relevant connected text like middle of sentence)
)
chunks = text_splitter.split_text(garfield_inaugural)
for chunk in chunks:
print(token_len(chunk))7. Embed Each Chunk into Semantic Vector Space
prompt_embeddings = embedding_function.embed_query(user_question) similarities = cosine_similarity([prompt_embeddings], chunk_embeddings)[0] closest_similarity_index = np.argmax(similarities) most_relevant_chunk = chunks[closest_similarity_index] display(HTML(most_relevant_chunk))
8. Use Cosine Similarity to Find the Most Relevant Chunk of Question
user_question = "What were James Garfield's views on civil service reform?" prompt_embeddings = embedding_function.embed_query(user_question) similarities = cosine_similarity([prompt_embeddings], chunk_embeddings)[0] closest_similarity_index = np.argmax(similarities) most_relevant_chunk = chunks[closest_similarity_index] display(HTML(most_relevant_chunk))
9. Feed the Most Relevant Chunk to LLM to Answer User Question
# A chat completion function that will use the most relevant exerpt(s) from presidential speeches to answer the user's question
def presidential_speech_chat_completion(client, model, user_question, relevant_excerpts):
chat_completion = client.chat.completions.create(
messages = [
{
"role": "system",
"content": "You are a presidential historian. Given the user's question and relevant excerpts from presidential speeches, answer the question by including direct quotes from presidential speeches. When using a quote, site the speech that it was from (ignoring the chunk)."
},
{
"role": "user",
"content": "User Question: " + user_question + "\n\nRelevant Speech Exerpt(s):\n\n" + relevant_excerpts,
}
],
model = model
)
response = chat_completion.choices[0].message.content
return response
model = "mixtral-8x7b-32768"
presidential_speech_chat_completion(client, model, user_question, most_relevant_chunk)Response from RAG
Now we have asked the same question to LLM after this RAG implementation, and the response was:
James Garfield, the 20th President of the United States, believed that the civil service needed to be regulated by law in order to be placed on a satisfactory basis. He thought that fixing the tenure of minor offices and prescribing the grounds for removals would protect those with appointing power, incumbents, and the efficiency of the public business. Garfield stated in his inaugural address, "The civil service can never be placed on a satisfactory basis until it is regulated by law.... I shall at the proper time ask Congress to fix the tenure of the minor offices of the several Executive Departments and prescribe the grounds upon which removals shall be made during the terms for which incumbents have been appointed." Furthermore, Garfield believed in the importance of honest and faithful service from all executive officers, stating, "I shall greatly rely upon the wisdom and patriotism of Congress and of those who may share with me the responsibilities and duties of administration, and, above all, upon our efforts to promote the welfare of this great people and their Government I reverently invoke the support and blessings of Almighty God."
Source:
Inaugural Address of James A. Garfield, March 4, 1881. Now, if you check this response, it’s concise, accurate, and to the point; there is no extra information, and it mentions the proper source as well, which increases the overall credibility.
Use Cases of RAG
Now we have understood the implementation of RAG using the Groq API in this particular use case. We have some other use cases as well where we can utilize the RAGs.
- Domain-Specific Chatbots:
RAGs are extremely useful when you have to develop domain-specific chatbots. You can provide the knowledge about your domain to LLM as an external knowledge base using RAGs, and it will answer the user queries keeping your knowledge base in mind.
- Fact Check
This is an interesting and very useful use case of RAGs. You can easily check whether the given claims are supported by facts or not using RAGs.
- Legal Research
RAGs can be very helpful in legal matters. Legal professionals can pull the relevant laws, cases, and legal writings.
Conclusion
Using RAGS with the Groq API, we can fully utilize the potential of LLMs in our domain-specific use cases. This implementation is just the tip of the iceberg in the landscape of LLMs.
If you want to learn more about LLMs, RAGs, APIs, or anything related to data, make sure to bookmark our blog section and keep visiting our website.
If you are a business owner and are interested in leveraging LLMs to optimize and grow your business, you can book a free meeting with us to discuss how we can help you make your business super efficient using data and AI.


